

The identification of molecules capable of specific protein-recognition is at the heart of modern drug discovery technologies.
With the advent of the new millennium, sequencing of the human genome as well as developments in proteomic research and transcriptomic analysis have massively aided the understanding of living systems and the discovery of a multitude of new biological targets associated with various human diseases.
On the other hand, the isolation of small-molecular probes capable of selectively recognizing such target protein still remains a formidable task.

Indeed, conventional approaches for the identification of specific and biologically active small molecular compounds (i.e., “high-throughput screening”) are very demanding, requiring the cubersome and time-consuming screening of very large chemical collections (“compound libraries”) comprising up to a few million compounds.
In the era of molecular medicine, there is an inevitable need to develop more efficient and versatile drug discovery techniques, capable of rapidly generating and interrogating massive collection of chemical compounds to tackle new target classes, too difficult to drug with traditional drug discovery approaches.
Latest Compound
WuXi AppTec, 22 Strathmore Road, Natick, MA 01760, USA
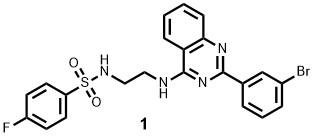
1 = 141 nM