

DNA-encoded chemical libraries can be efficiently synthesized by straight DNA-conjugation of building blocks and reagents in combinatorial fashion.
Figure 5 schematically depicts a typical “pool-split-pool” strategy for library assembly as described for the first time by Neri and coworkers in 2008.
Overall, it comprises five sequential steps:
i). Coupling of a first set of n chemical compounds (i.e., n = 20) to n unique 5’-reactive-oligonucleotides (i.e., synthetic 5’-amino-oligonucleotide).
ii). Characterization and generation of the first sub-library pool.
iii). Splitting of the sub-library pool into m reaction vessels and incorporation of the second set of building blocks (i.e., m = 200).
iv). Enzymatic DNA-encoding (i.e., by Klenow-assisted DNA-polymerization) to univocally encode the identity of the second chemical moiety incorporated.
v). Pooling of the encoded reactions to yield the final n x m DNA-encoded chemical library.
In principle, depending on the reactivity of the initial building blocks, the process as described above can be iterated to introduce additional sets of compounds and rapidly generate libraries comprising over 108 DNA-encoded small molecules.
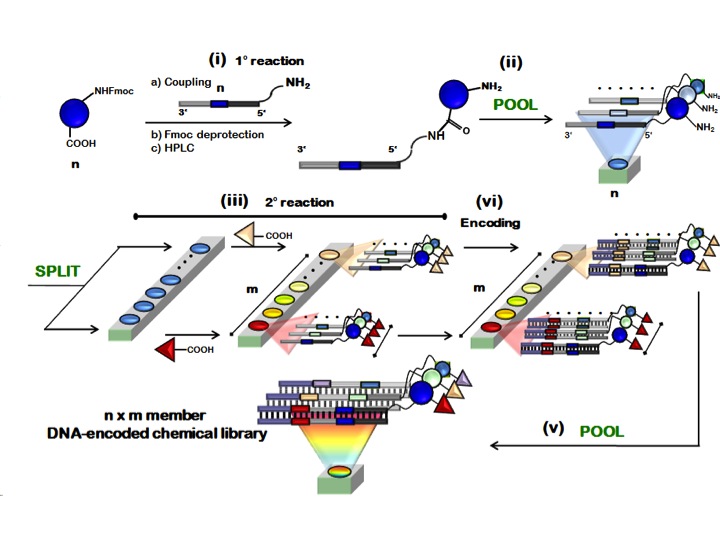
Figure 5: “pool-split-pool” strategy for the construction of DNA-conjugate chemical libraries. Copyright (2008) National Academy of Sciences, U.S.A.
Proof-of-concept high-throughput sequencing analysis performed on a library comprising 4’000 compounds before and after selection on streptavidin-coated beads revealed the enrichment of the expected desthiobiotin positive control as well as of other structurally related streptavidin-binding compounds (Figure 6). This workrepresents the first application of deep-sequencing technology to the decoding of DNA-encoded chemical library selections.
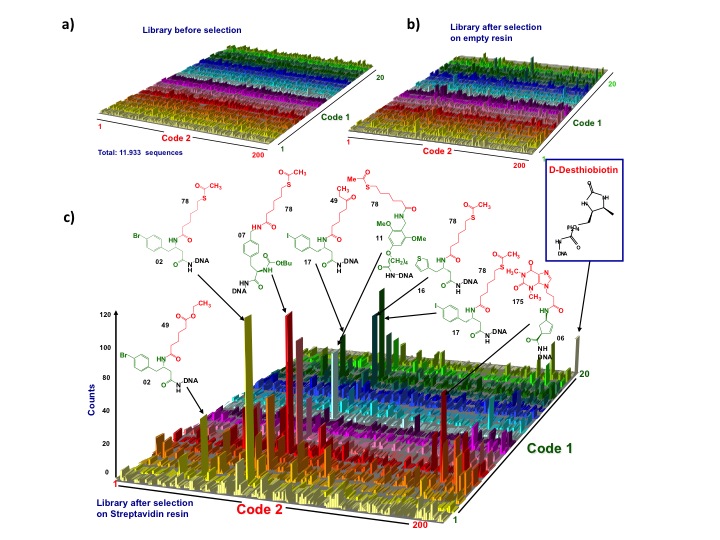
Figure 6: high-throughput sequencing dcoding of a DNA-conjugate library (a-c) Plots representing a 4’000 member library(x-y plane) and the corresponding sequence counts (z axis). a, b) High-throughput sequencing of the library before and after selection on empty resin revealed homogeneous distribution of the counts over all the library members. c) Streptavidin selection sequencing showed a preferential enrichment of D-desthiobiotin (KD = 4nM positive control spiked into the library prior to selection) and of other structurally related compounds. The chemical structures of some of the most relevant straptavidin ligands are reported together with the library identification number. Building blocks used in the 2 synthetic “pool-split-pool” steps are highlighted in green and red, respectively. Selected molecules(>30 counts) exhibited afer re-synthesis binding toward streptavidin, with KD values ranging between 350nM and 11mM. In contrast, low-enriched structures (<10 counts) did not exhibit appreciable binding to streptavidin (KD > 50mM. Copyright (2008) National Academy of Sciences, U.S.A.
DNA-conjugate libraries are particularly suitable for the optimization of previously discovered lead structures. Such focused DNA-encoded chemical libraries (also termed “affinity maturation libraries”) can be efficiently synthesized incorporating a known a lead structure during the combinatorial assembly.
Figure 7 shows a 8’000 (40 x 200) member benzamidine-based ‘‘affinity maturation’’ library assembled by sequential addition of two different sets of building blocks onto a 4-carbamimidoylbenzyl) glutamamide core structure. After selection on a trypsin-coated resin, this library allowed the isolation of a >10’000-fold improved benzamidine-based trypsin inhibitor, with single-digit nanomolar potency and excellent selectivity over closely related serine proteases.
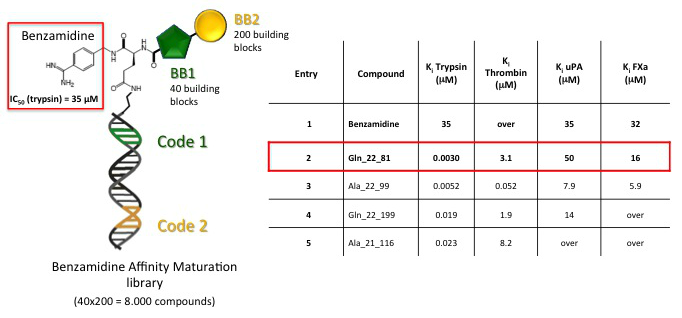
Figure 7: benzamidine-based ‘‘affinity maturation’’ library. After selection on trypsin-coated resin, a >10’000-fold improved benzamidine-based trypsin inhibitor with single-digit nanomolar potency and excellent selectivity over closely related serine proteases has been identified.
Even though DNA-conjugate library containing billions of chemical entities can be quickly generated by combinatorial assembly of multiple sets of building blocks, the real benefit of larger chemical libraries (comprising more than 106-107 compounds) is still under debate due to a various practical limitations(purity of the resulting library, problems associated with the decoding by high-throughput sequencing) and “drug-likeness” of the final molecular structures. Additionally, since library size and chemical diversity are intimately connected to the number of combinatorial steps and building blocks used for library construction, repertoires comprising up to few millions of compounds are typically of superior quality and contain compounds which may better fulfill drug-like requirements (Figure 8).
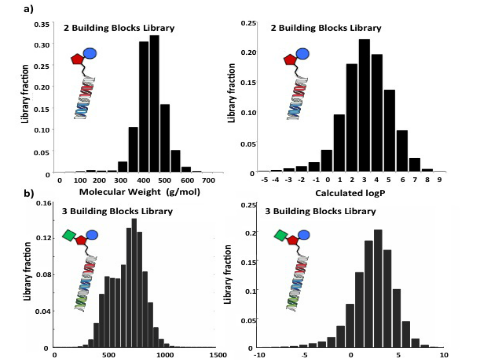
Figure 8: Molecular weight and logP distribution of two different DNA-conjugate libraries. a)Two building blocks (two cycles of pool-split-pool) library (up to 106 compounds. b) Three building blocks (three cycles of pool-split-pool) library (up to 108-109 compounds). Small libraries may contain compounds, which better fulfill drug-like requirements. Reproduced by permission of Elsevier (http://www.sciencedirect.com/science/article/pii/S0960894X10006943).
OBOC („One-Bead-One-Compound”) DECL
OBOC DECL Concept
Applying combinatorial chemistry principles to solid phase synthesis, it is possible to generate microbeads-supported chemical libraries, termed “one-bead-one-compound” (OBOC) libraries. Each bead carries many copies of a single compound and the methodology holds a great potential for the rapid identification of novel hits against a protein (drug) target. However, this potential is very cumbersome to fully realize, given a number of technical obstacles. One of the major bottleneck is that, while a OBOC library of millions of compounds can be readily synthesized applying split-and-pool methodologies, the screening and “decoding” of millions of beads by conventional analytical methods is very cumbersome and challenging, especially for routine drug-discovery applications. However, introducing DNA-coding of the OBOC-microbeads, the screening and decoding tasks can be successfully accomplished using water-in oil emulsion droplet microfluidics and next generation sequencing respectively (see example in Figure 27).
OBOC DECL Synthesis
DNA-encoded solid-phase synthesis (DESPS) is typically employed to the assembly of OBOC DECLs. DESPS requires a bifunctional linker for enabling the parallel chemical synthesis and enzymatic DNA-based encoding. The assembly is usually performed alternating the chemical modification of the core scaffold attached to the bead, to the substoichiometric enzymatic DNA-encoding in split-and-pool fashion (Figure 26). Eventually, the final DESPS product is a resin-bound oligomeric compound carrying an encoding DNA-tag. Depending on bead size, each OBOC library microbead can display up to 10−15−10−9 moles of an individual library member.
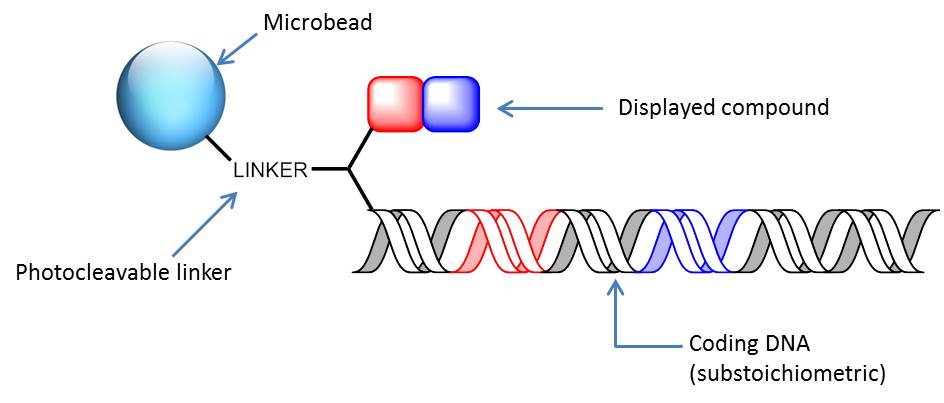
Figure 26: OBOC DECL member. Microbeads (160-μm diameter) is first elaborated with a common photocleavable linker. The linker-resin is further connected to a bifunctional spacer. The synthesis proceeds as alternating split-&-pool steps of monomer coupling and DNA-coding. The initial DNA-tagging is performed substoichiometrically (i.e., only a portion of the molecule displayed on the beads are DNA-tagged).
OBOC DECL Selection (“Sorting”)
Most of the DECL technologies which has been developed relies on affinity-based hit identification (“panning”), however these libraries are “refractory” to any biochemical or cellular activity selection pressure. In order to introduce the activity-based screen to the DECL selections, many copies of an individual library member must be localized in a discrete volume, and this can be conceptually achieved using OBOC DECLs.
The use of water-in oil emulsion droplet microfluidics as developed by Paegel and co-workers is crucial for the automation of the OBOC DECL selection strategy. The droplet encapsulate the library bead together with the screening components (Figure 27A). In each droplet, the library compound is photochemically cleaved (Figure 27B) from the bead during the transit towards the incubation chamber (Figure 27C). Eventually the assay-positive droplets are selected (“sorted”; Figure 27D) and submitted to high-throughput DNA sequencing decoding (Figure 27E).
The microfluidic device enables the homogenous generation of picoliter incubation incubation chambers, and generates appropriate concentrations for the screening of femto-moles of material.
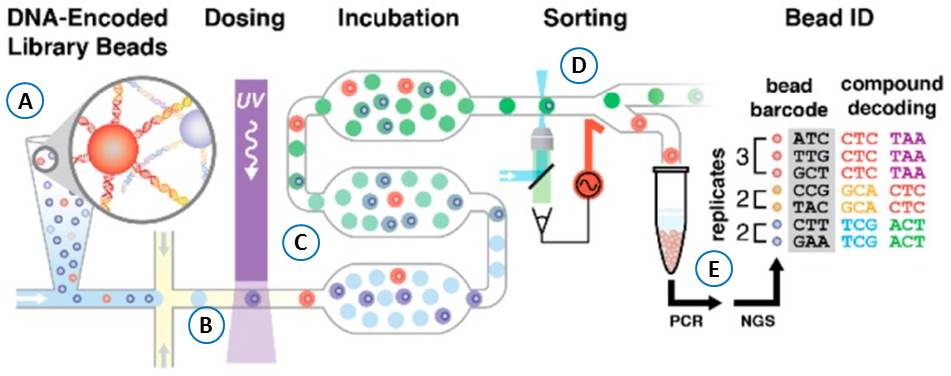
Figure 27: OBOC DECL Selection & Sorting. Water oil-emulsion containing assay components and OBOC library are mixed and droplets formed (A). Droplets flow through a serpentine channel, where an integrated waveguide irradiates droplets with UV, photochemically liberating compound from the bead into the droplet volume (B). Droplets then flow into a deep incubation channel/chamber (C) before auxiliary oil inputs separate and guide droplets at the sorting junction where confocal laser-induced fluorescence controls the sorting (D). The DNA of the selected droplet hits is PCR-amplified and decoded after high-throughput sequencing (E).